Guia definitivo de Análise de Causa Raiz (RCA) para times de suporte e ITSM: o que é, por que importa, os métodos clássicos (5 Porquês, Ishikawa, FMEA), como aplicar no help desk passo a passo, exemplos reais e como o módulo Relatório de Causa-Raiz da Service Up automatiza isso dentro do Znuny com IA.
⚡ Versão de 30 segundos
- RCA (Root Cause Analysis / Análise de Causa Raiz) é o método de descobrir por que um problema aconteceu — não só resolver o sintoma do chamado, mas eliminar a causa para que ele não volte.
- No help desk, sem RCA você vira refém do retrabalho: o mesmo incidente reabre toda semana, infla o volume de chamados e corrói a confiança do cliente. RCA quebra esse ciclo.
- Os três métodos que todo time de suporte deveria conhecer: 5 Porquês (rápido e direto), Diagrama de Ishikawa/espinha de peixe (mapeia categorias de causa) e FMEA (antecipa falhas antes que aconteçam).
- Fazer RCA manual em todos os chamados é inviável — por isso a maioria dos times só investiga os incidentes graves. A IA muda essa conta: dá para analisar centenas de chamados em escala.
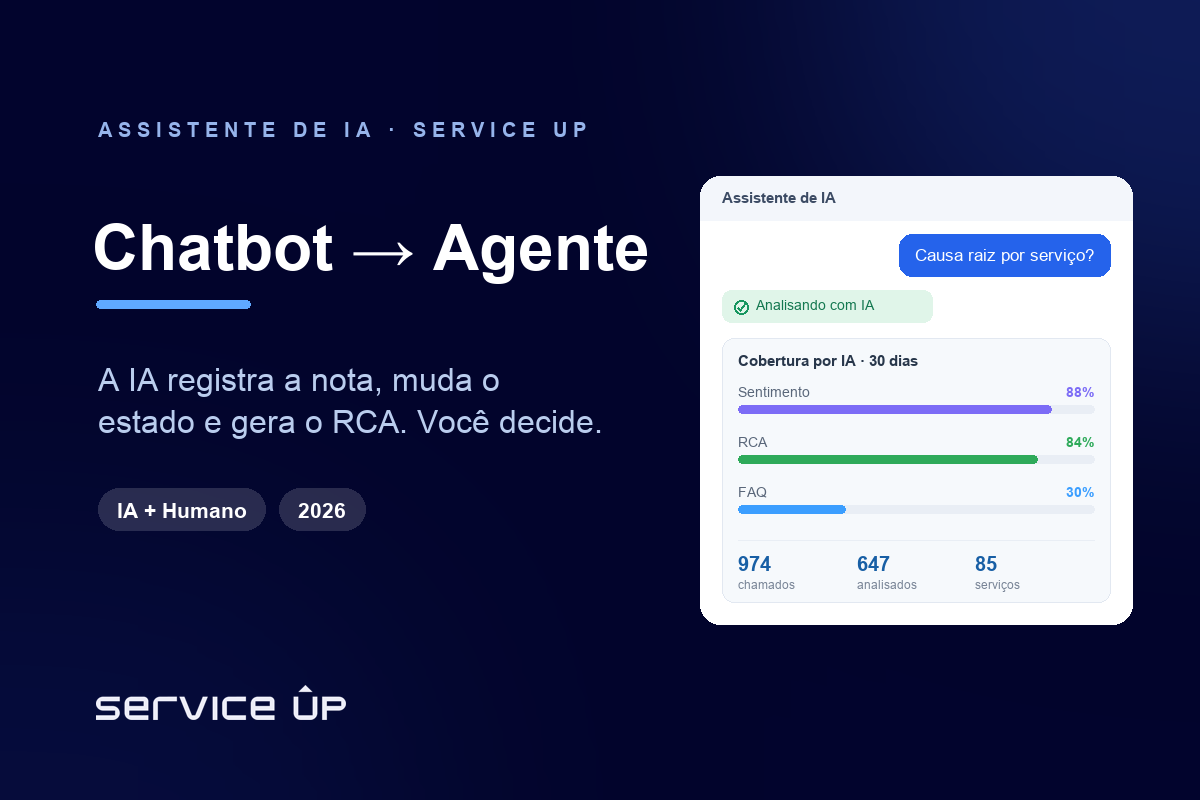
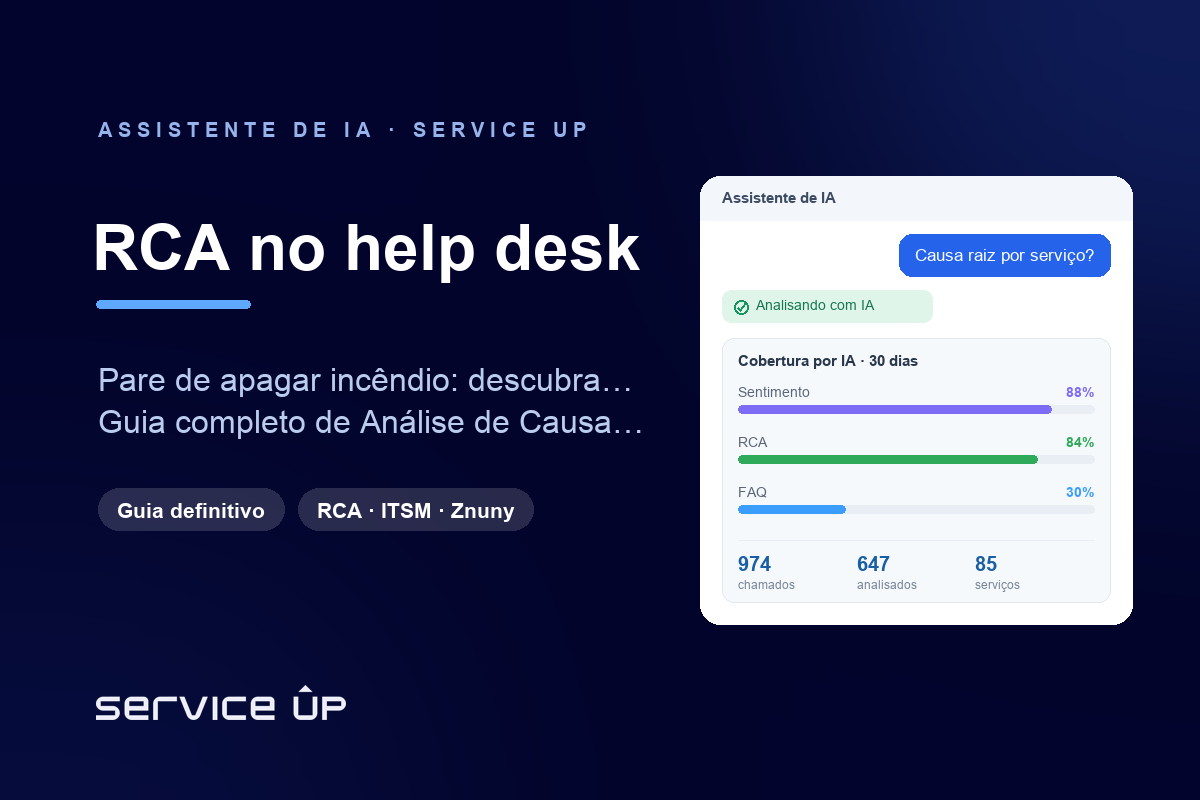
- O módulo Relatório de Causa-Raiz da Service Up roda dentro do Znuny e usa IA (DeepSeek) para gerar RCA por chamado e um painel agregado por serviço. Em 30 dias, 647 de 974 chamados foram analisados no painel (66%) e a cobertura de RCA chegou a 84% dos chamados elegíveis. A IA acelera; o humano decide.
O que é Análise de Causa Raiz (RCA), em uma frase
Análise de Causa Raiz (Root Cause Analysis, ou RCA) é o processo estruturado de identificar a origem real de um problema — e não apenas o sintoma visível. No help desk, o sintoma é o chamado que chega; a causa raiz é o que faz aquele chamado existir. Resolver o sintoma fecha o ticket de hoje; eliminar a causa impede os dez chamados de amanhã. É por isso que fazer Análise de Causa Raiz no help desk deixou de ser um luxo de times grandes e virou questão de sobrevivência operacional.
A distinção é a alma do tema. Apagar incêndio é tratar cada chamado como um evento isolado: reiniciar o serviço, limpar o cache, orientar o usuário e fechar. Funciona — até o problema voltar. RCA pergunta a pergunta incômoda: por que isso aconteceu, de verdade? E continua perguntando até chegar a algo que, se corrigido, faz o sintoma desaparecer para sempre.
Em ITSM, a RCA é o coração do Problem Management (Gestão de Problemas), uma das práticas da ITIL. Enquanto a Gestão de Incidentes existe para restaurar o serviço o mais rápido possível, a Gestão de Problemas existe para descobrir por que o incidente ocorreu e impedir sua recorrência. RCA é a ferramenta que conecta as duas.
- Sintoma: o chamado, o erro na tela, o serviço fora do ar — o que o usuário percebe.
- Causa imediata: o que disparou o sintoma agora (um disco cheio, uma senha expirada).
- Causa raiz: a falha de origem que, se corrigida, impede a recorrência (falta de monitoramento de disco, política de senha mal configurada).
Por que RCA importa no help desk: o custo de apagar incêndio
Todo time de suporte conhece a sensação: o chamado é fechado, todo mundo respira, e na semana seguinte ele volta — às vezes com outro nome, mas a mesma causa por baixo. Esse é o ciclo do apaga-incêndio. Ele consome a equipe, mascara o tamanho real do problema e transforma o suporte numa esteira que nunca esvazia.
Sem RCA, o volume de chamados é uma soma de incidentes que se repetem. Com RCA, cada causa eliminada apaga uma fileira inteira de chamados futuros. A diferença, ao longo de meses, é gigante: um time que investiga causas trabalha cada vez menos no mesmo problema; um time que só fecha tickets trabalha cada vez mais.
O ganho é composto. Cada causa raiz eliminada não resolve um chamado — resolve toda a série futura daquele problema. É por isso que times maduros tratam a RCA não como burocracia pós-incidente, mas como o principal mecanismo de redução de demanda do suporte.
- Retrabalho: o mesmo incidente reabre repetidamente, inflando o volume sem agregar valor.
- Erosão de confiança: o cliente percebe que o problema ‘nunca é resolvido de verdade’.
- SLA sob pressão: incidentes recorrentes empilham e estouram prazos.
- Conhecimento perdido: sem registrar a causa, cada novo analista recomeça do zero.
A operação inteira · painel de causa-raiz
Recriação do painel real (Ferramentas → AI Copilot · Relatório de Causa-Raiz).
Os 3 métodos de RCA que todo time de suporte deveria conhecer
Não existe um único jeito de fazer RCA — existe um método certo para cada situação. Três deles cobrem a esmagadora maioria dos casos no suporte e em ITSM.
1. Os 5 Porquês. O mais simples e o mais usado. Você pega o sintoma e pergunta ‘por quê?’ repetidamente — geralmente cerca de cinco vezes — até chegar a uma causa que não tem um ‘porquê’ acionável acima dela. Exemplo: o serviço caiu (por quê?) → o disco encheu (por quê?) → os logs não rotacionavam (por quê?) → não havia política de rotação (por quê?) → ninguém definiu o padrão no provisionamento. A causa raiz não era o disco; era o processo de provisionamento. Rápido, ótimo para incidentes diretos.
2. Diagrama de Ishikawa (espinha de peixe). Quando um problema tem várias causas possíveis, o Ishikawa organiza as hipóteses em categorias — pessoas, processo, tecnologia, ambiente, dados — desenhadas como espinhas saindo de uma seta central. Force a equipe a preencher cada categoria e os pontos cegos aparecem. Ideal para incidentes complexos ou recorrentes em que ninguém tem certeza da causa.
3. FMEA (Análise de Modos de Falha e Efeitos). O mais preventivo dos três. Em vez de analisar um incidente que já aconteceu, o FMEA mapeia falhas potenciais antes que ocorram, pontuando cada uma por severidade, frequência (ocorrência) e detecção. É a RCA virada para o futuro — útil para serviços críticos e mudanças de alto risco.
- 5 Porquês: rápido, conversacional, perfeito para o dia a dia do help desk.
- Ishikawa: visual e colaborativo, bom para causas múltiplas e ambíguas.
- FMEA: estruturado, preventivo, ótimo para risco e serviços críticos.
Como aplicar RCA no help desk, passo a passo
RCA não precisa ser um ritual pesado. No fluxo de suporte, ela cabe em seis passos que qualquer time consegue adotar — começando pelos incidentes recorrentes ou de alto impacto, que são os que mais doem.
A regra de ouro: só pare de perguntar ‘por quê?’ quando a causa encontrada, se corrigida, realmente impedir a recorrência. Se a sua ‘causa raiz’ ainda admite um sintoma futuro, você parou cedo demais.
O segredo está no passo final: a RCA só gera valor se a ação corretiva for executada e se o aprendizado virar conhecimento reutilizável (FAQ, base de conhecimento, regra de monitoramento). Análise que termina num documento esquecido é só mais retrabalho.
- 1. Defina o problema com precisão: o que falhou, quando, para quem, com que frequência.
- 2. Monte a linha do tempo: ordene os eventos do chamado, do primeiro sinal ao fechamento.
- 3. Colete evidências: logs, prints, histórico de chamados parecidos, sentimento do cliente.
- 4. Aplique um método: 5 Porquês para casos diretos, Ishikawa para os ambíguos.
- 5. Valide a causa: confirme que ela explica todos os sintomas, não só alguns.
- 6. Registre e compartilhe: vire FAQ, artigo de base de conhecimento ou alerta proativo — para o time inteiro reaproveitar.
Exemplo real: um gap de 29 dias que a RCA explica
No módulo da Service Up, um dos chamados analisados — o #2685787 — apresentava um gap de cerca de 29 dias na linha do tempo. Esse tipo de intervalo é exatamente o que a RCA caça: por que o chamado ficou parado quase um mês? Espera por terceiro? Dependência de outro time? Falta de SLA definido para aquela categoria? O gap é o sintoma; a causa está no porquê do gap.
Esse exemplo mostra por que a linha do tempo é tão central na RCA. Sem ela, você vê o resultado (chamado demorou) e não a história (onde, exatamente, ele travou). Com ela, o ponto de atrito fica visível e a investigação tem onde ancorar.
Outro sinal que o painel expõe: 182 chamados estavam sem serviço vinculado (‘No linked service’). Isso, por si só, é uma causa raiz de processo — sem vínculo, esses chamados escapam de qualquer análise agregada por serviço. A RCA não só explica incidentes; ela ilumina as lacunas do próprio processo de registro.
RCA manual não escala — e é aí que entra a IA
O grande problema da RCA não é o método; é o tempo. Investigar a causa raiz de um único chamado pode levar de minutos a horas: ler todo o histórico, reconstruir a linha do tempo, cruzar com casos parecidos. Multiplique por centenas de chamados por mês e fica claro por que a maioria dos times só faz RCA nos incidentes mais graves — o resto é fechado no modo apaga-incêndio.
É essa conta que a IA reescreve. O módulo Relatório de Causa-Raiz da Service Up — que roda dentro do Znuny, a plataforma de ITSM/help desk — usa IA (motor DeepSeek, modelo deepseek-chat) para ler os chamados e produzir a análise em escala. Ele tem duas faces: por chamado, gera um relatório RCA completo em PDF com 8 seções (resumo executivo, linha do tempo, análise de gaps e causa raiz, sentimento, status técnico, recomendações, métricas e conclusão); no painel agregado, mostra os chamados do período agrupados por serviço vinculado, com a causa raiz da IA como detalhe.
Os números do período de 30 dias dão a dimensão: 974 chamados, dos quais 647 foram analisados no painel (66%), distribuídos em 85 serviços, com cobertura de RCA de 84% sobre os chamados elegíveis. O processamento é sob demanda (‘Processar agora’) ou em lote pelo console. O serviço com mais chamados no período foi ‘Consultoria::Dúvida’, com 142.
Importante: a IA não substitui o analista. Ela faz o trabalho pesado de leitura e estruturação para que a pessoa decida a ação corretiva com contexto. A tese da Service Up é direta — a IA acelera; o humano decide. O ganho não é demitir; é dar autonomia e tempo de volta ao time.
- Por chamado: relatório RCA em PDF com 8 seções, incluindo linha do tempo e análise de gaps.
- Por serviço: painel agregado do período, agrupado por serviço vinculado, com a causa raiz da IA.
- Em escala: 647 chamados analisados em 30 dias — inviável de fazer só no braço.
- Além da RCA: busca semântica, análise de sentimento, tempo vs SLA, gráficos sob demanda e panorama.
Resumo: do incêndio à causa, em uma página
RCA é o método que separa o time que fecha chamados do time que resolve problemas. Sem ela, o suporte vira uma esteira de retrabalho; com ela, cada causa eliminada apaga uma fileira de chamados futuros. Os métodos clássicos — 5 Porquês, Ishikawa e FMEA — cobrem do caso mais simples ao mais crítico, e o fluxo de seis passos cabe na rotina de qualquer help desk.
O que mudou nos últimos anos é a escala. RCA manual nunca chegou a todos os chamados porque o tempo não dava. Com IA lendo o histórico, reconstruindo a linha do tempo e propondo a causa, dá para investigar centenas de chamados — e o analista entra onde mais importa: validar e decidir a ação corretiva.
O Relatório de Causa-Raiz é um módulo da Service Up, nativo do Znuny, pensado exatamente para isso: gerar a RCA por chamado e o panorama agregado por serviço, deixando a decisão — e o crédito — com o seu time. Se você convive com o ciclo de chamados que voltam toda semana, esse é o ponto de partida para quebrá-lo.
🔧 Para os técnicos
Abra só o que te interessa.
Qual a diferença entre Gestão de Incidentes e RCA / Gestão de Problemas na ITIL?
A Gestão de Incidentes existe para restaurar o serviço o mais rápido possível — foco em velocidade e em fechar o chamado. A RCA é a ferramenta central da Gestão de Problemas, cujo objetivo é descobrir por que o incidente ocorreu e impedir sua recorrência. Na prática: incidente é o ‘agora, resolva’; problema é o ‘nunca mais’. Um incidente recorrente é o gatilho clássico para abrir uma análise de causa raiz formal.
Como a IA do módulo gera a RCA e em quanto da base ela consegue rodar?
O motor é o DeepSeek (deepseek-chat). Ele lê o histórico do chamado e produz a análise estruturada. O disparo é por chamado (‘Processar agora’) ou em lote pelo console: bin/znuny.Console.pl Maint::AICopilot::RCAScan. No período medido de 30 dias, a cobertura de RCA foi de 84% sobre os chamados elegíveis, e 647 dos 974 chamados (66%) foram analisados no painel. A análise de sentimento cobriu 88% e a geração de FAQ, 30% — sinal de que o módulo faz mais do que RCA. A decisão sobre a ação corretiva continua sendo do analista.
O que exatamente vem no relatório RCA por chamado?
Um PDF com 8 seções: (1) resumo executivo, (2) linha do tempo, (3) análise de gaps e causa raiz, (4) sentimento, (5) status técnico, (6) recomendações, (7) métricas e (8) conclusão. A seção de gaps é a que captura intervalos como o do chamado #2685787 — um gap de cerca de 29 dias — e tenta atribuí-lo a uma causa. No painel agregado, em vez do PDF individual, você vê os chamados do período agrupados por serviço vinculado (85 serviços no período), com a causa raiz da IA como detalhe de cada grupo.
RCA com IA não corre o risco de ‘inventar’ causa raiz?
Por isso o desenho é assistivo, não autônomo. A IA estrutura evidências (linha do tempo, gaps, sentimento, status técnico) e propõe hipóteses de causa — o analista valida contra os logs e o histórico antes de definir a ação corretiva. É o mesmo rigor da RCA manual (validar se a causa explica todos os incidentes), só que com o trabalho de leitura já adiantado. Sinais como os 182 chamados ‘sem serviço vinculado’ mostram, inclusive, onde os próprios dados são frágeis — o que reforça a necessidade do olhar humano.
Este módulo é parte do AI Copilot da Service Up
Somos especialistas em ITSM e help desk (parceira Znuny/OTOBO). O AI Copilot já roda no nosso ambiente — e pode rodar no seu.
Quer ver a RCA automática rodando na sua operação? Fale com a Service Up no WhatsApp: +55 11 5192-3351
Converse com o nosso time comercial e veja a IA aplicada ao seu atendimento.
Falar com o comercial no WhatsApp+55 11 5192-3351