Um guia prático de gestão de backlog de chamados: como medir aging, priorizar com critério e estancar o crescimento, com o módulo Insights da Service Up compilando o relatório gerencial todo dia, direto no seu e-mail.
⚡ Versão de 30 segundos
- Backlog cresce quando a entrada supera a saída de chamados. O problema raramente é esforço; quase sempre é processo, priorização e visibilidade.
- Meça quatro coisas: tamanho do backlog, aging (idade dos chamados parados), taxa de entrada x saída e distribuição por estado. Sem aging, você só vê a foto, não o filme.
- Priorize por impacto x urgência x idade, não por quem grita mais. Chamados antigos parados em estados passivos (pendente com cliente, aguardando validação) são os que mais sangram.
- Para estancar: ataque o aging mais velho primeiro, defina limites por estado, automatize follow-ups e revise a distribuição de fila com recorrência.
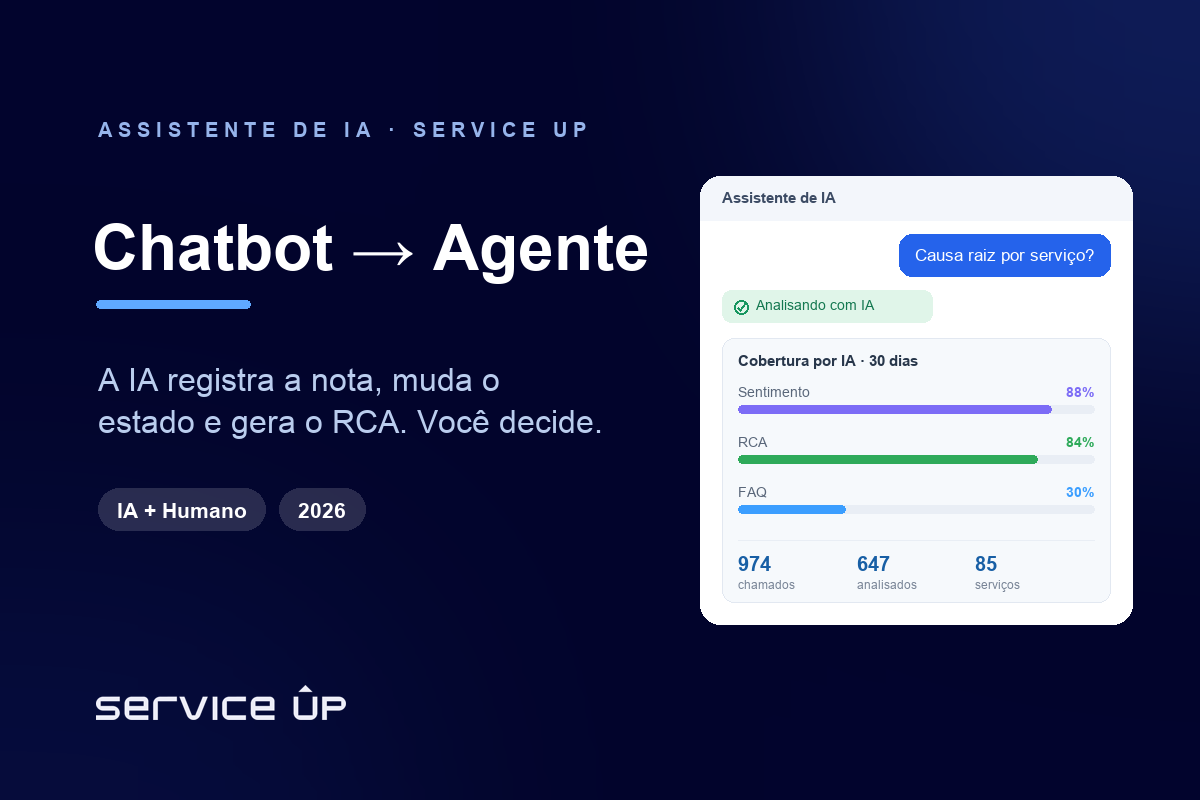
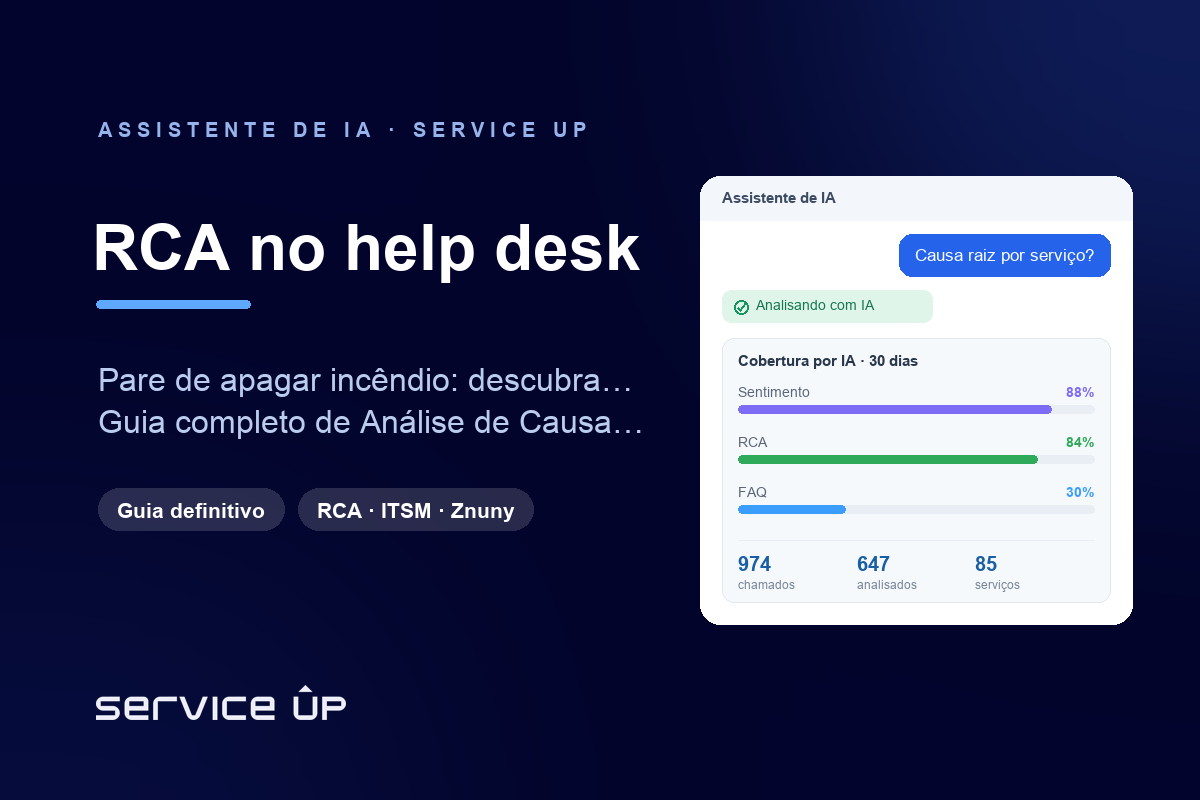
- O Insights, módulo de IA dentro do Znuny, compila esse relatório gerencial sozinho, agendado por cron, e entrega por e-mail. A IA compila; o humano decide.
O que é backlog em ITSM (e por que ele cresce)
Backlog, em ITSM, é o conjunto de chamados abertos que ainda não foram resolvidos. Ele é natural: nenhuma operação zera o quadro o tempo todo. O problema não é ter backlog, é ter um backlog que só cresce, mês após mês, sem que ninguém saiba exatamente por quê.
A mecânica é simples e implacável: se a taxa de entrada de chamados supera a taxa de saída (resolução), o acúmulo é questão de tempo. E quando isso acontece de forma crônica, a causa quase nunca é falta de empenho da equipe. É processo: priorização confusa, chamados parados em estados passivos, falta de limites e, acima de tudo, falta de visibilidade gerencial recorrente.
Por isso a tese deste guia: backlog que só cresce é sintoma de processo, não de preguiça. Tratar como falta de esforço gera pressão na equipe e nenhum resultado. Tratar como problema de medição e priorização resolve.
- Entrada > saída = backlog crescente (lei básica de filas)
- A causa raiz costuma ser processo, não volume de trabalho
- Sem medição recorrente, o backlog vira um número que assusta mas não orienta
Os 4 KPIs que você precisa medir
Gestão de backlog de chamados começa pela medição certa. Quatro indicadores dão o quadro completo. O erro mais comum é olhar só o tamanho do backlog (um número grande e assustador) e ignorar os outros três, que explicam o porquê.
- Tamanho do backlog: total de chamados abertos. Útil como termômetro, mas sozinho não diz nada sobre saúde. No exemplo de referência, ~668 chamados abertos.
- Aging (idade dos chamados): há quanto tempo cada chamado está aberto e parado. É o KPI mais negligenciado e o mais revelador. Um backlog de 600 chamados novos é saudável; 600 chamados com mais de 30 dias é uma crise.
- Taxa de entrada x saída: quantos chamados entram e quantos saem por período. Se entram mais do que saem, o backlog cresce por definição. Esse é o KPI que prevê o futuro.
- Distribuição por estado: onde os chamados estão parados. No exemplo de referência: em atendimento ~180, pendente com cliente ~120, aguardando validação ~60, aberto ~50, novo ~40. Estados passivos concentram o aging silencioso.
Veja em ação · relatório gerado por IA
Relatório escrito pela IA sobre os chamados abertos (dados agregados).
Aging: o filme, não a foto
Se você só puder medir uma coisa nova, meça aging. O tamanho do backlog é uma foto; o aging é o filme. Ele responde à pergunta que importa: dos chamados abertos, quantos estão envelhecendo sem movimento?
A forma prática é agrupar por faixas de idade: 0-3 dias, 4-7 dias, 8-15 dias, 16-30 dias e mais de 30 dias. A distribuição dessas faixas revela tudo. Se a maioria está nas faixas curtas, o backlog respira. Se há uma cauda longa acima de 30 dias, você tem chamados esquecidos drenando a operação.
Atenção especial aos estados passivos: pendente com cliente e aguardando validação são onde chamados envelhecem fora do radar, porque parecem que não são mais responsabilidade da equipe. São. Um chamado pendente há 25 dias sem follow-up não é do cliente, é da gestão que não cobrou.
- Agrupe o aging em faixas (0-3, 4-7, 8-15, 16-30, 30+ dias)
- Cauda longa acima de 30 dias = chamados esquecidos = sintoma de processo
- Estados passivos (pendente, aguardando validação) escondem o pior aging
Como priorizar sem priorizar por quem grita mais
A priorização informal (atender quem reclama mais alto) é o atalho que perpetua o backlog. Os chamados silenciosos, sem padrinho, são justamente os que envelhecem. Priorização precisa de critério explícito.
Um modelo robusto cruza três dimensões: impacto (quantos usuários ou processos são afetados), urgência (qual o prazo real ou risco de SLA) e idade (há quanto tempo o chamado espera). A idade entra na conta de propósito: é o fator que impede chamados antigos de afundarem indefinidamente.
Na prática, isso vira uma fila de trabalho ordenada que combina os críticos novos com os antigos esquecidos. Sem o componente de idade, você sempre atende o último que chegou e nunca limpa a cauda. Com ele, o aging mais velho sobe naturalmente para o topo.
- Priorize por impacto x urgência x idade, com critério escrito
- Inclua a idade na fórmula para não abandonar a cauda do backlog
- Documente o critério: priorização informal sempre favorece quem grita
Como estancar: parar de crescer antes de zerar
Tentar zerar o backlog de uma vez é desmotivante e raramente funciona. A meta inicial certa é estancar: fazer a saída igualar ou superar a entrada. Quando o backlog para de crescer, você já recuperou o controle; reduzir vem depois.
Quatro alavancas concretas funcionam na maioria das operações. Comece sempre pelo aging mais velho, porque são os chamados de maior risco reputacional e os que mais distorcem suas médias.
Some a isso uma revisão recorrente da distribuição de fila. No exemplo de referência, ~45% do backlog se concentra em uma única fila (Consultoria). Concentração assim é um sinal: pode indicar falta de capacidade, escopo mal definido ou demanda que deveria virar projeto. Sem olhar a distribuição com regularidade, esse desequilíbrio passa batido.
- Ataque primeiro o aging mais velho (30+ dias), não o mais recente
- Defina limites por estado (ex.: nenhum chamado pendente sem follow-up por mais de X dias)
- Automatize follow-ups dos estados passivos para o aging não crescer sozinho
- Revise a distribuição por fila com recorrência; concentração alta é sinal de processo
Onde o Insights da Service Up entra
Tudo acima exige uma coisa que falta na maioria das operações: visibilidade recorrente. Ninguém gerencia backlog olhando o painel uma vez por mês. O dado precisa chegar, pronto e interpretado, na mesa de quem decide, todo dia.
O Insights é o módulo de IA Copilot da Service Up dentro do Znuny. É uma biblioteca de prompts sobre os chamados abertos: você escolhe ou cria um prompt (como uma Análise do Backlog), executa sob demanda ou agenda via cron (por exemplo, 0 6 * * * para rodar todo dia às 06:00) e o resultado é entregue por e-mail aos destinatários certos. A IA escreve o relatório gerencial, com seções de resumo do período, distribuição por estado, tempo de primeira resposta e mais, sempre em termos agregados.
A tese é clara e é a mesma de todo o ecossistema Service Up: a IA compila o relatório, o humano decide. O Insights não substitui a gestão, automatiza o relatório gerencial e dá a visibilidade proativa que torna a gestão de backlog possível. Ele é complementar ao módulo RCA, que analisa causa raiz por chamado; o Insights é a visão gerencial recorrente sobre o conjunto. Quer ver isso rodando na sua operação? Fale com a Service Up no WhatsApp comercial +55 11 5192-3351.
- Biblioteca de prompts sobre os chamados abertos, executados sob demanda ou por cron
- Relatório gerencial compilado pela IA e entregue por e-mail (filtros por fila e data, histórico de versões)
- Complementar ao RCA: o RCA olha causa raiz por chamado; o Insights dá a visão gerencial do backlog
🔧 Para os técnicos
Abra só o que te interessa.
Como calcular aging na prática dentro de um help desk ITSM?
Para cada chamado aberto, aging = data de referência menos data de abertura (ou menos a data do último movimento, se você quiser medir estagnação em vez de idade total). Agrupe em faixas (0-3, 4-7, 8-15, 16-30, 30+ dias) e cruze com o estado. O cruzamento aging x estado é o mais revelador: ele expõe chamados em estados passivos (pendente com cliente, aguardando validação) que estão envelhecendo sem ninguém cobrar. O Insights compila exatamente esse tipo de corte de forma agregada, sem citar chamados, clientes ou analistas individuais.
Qual a diferença entre backlog crescente e backlog grande?
São problemas distintos. Backlog grande é uma questão de capacidade ou de limpeza pontual (mutirão). Backlog crescente é estrutural: a taxa de entrada supera a de saída ao longo do tempo. Você diagnostica medindo entrada x saída por período. Se a curva de saída não acompanha a de entrada, nenhum mutirão resolve, porque o crescimento volta. A correção é de processo: priorização com critério, limites por estado e automação de follow-up nos estados passivos.
Como o agendamento por cron funciona no Insights?
O Insights aceita expressões cron padrão para disparar um prompt automaticamente. Por exemplo, 0 6 * * * executa todo dia às 06:00; o relatório é gerado pela IA e enviado por e-mail aos destinatários configurados. Você pode aplicar filtros por fila e por data, e o módulo mantém histórico de versões do prompt. A prática recomendada para gestão de backlog é uma execução diária cedo, para a equipe começar o dia com a foto do aging e da distribuição por estado já pronta na caixa de entrada.
O Insights expõe produtividade individual ou nomes de clientes?
Não. Por princípio e por LGPD, o relatório fala sempre em termos agregados: total de backlog, distribuição por estado, faixas de aging, mediana de primeira resposta e quantidade de analistas (apenas o número). Não há exposição de nomes de clientes, e-mails ou produtividade individual de funcionários. A visão gerencial é construída sobre agregados, que é o nível certo para decidir processo sem violar privacidade.
Este módulo é parte do AI Copilot da Service Up
Somos especialistas em ITSM e help desk (parceira Znuny/OTOBO). O AI Copilot já roda no nosso ambiente — e pode rodar no seu.
Quer ver o relatório de backlog chegando no seu e-mail todo dia?
Converse com o nosso time comercial e veja a IA aplicada ao seu atendimento.
Falar com o comercial no WhatsApp+55 11 5192-3351